


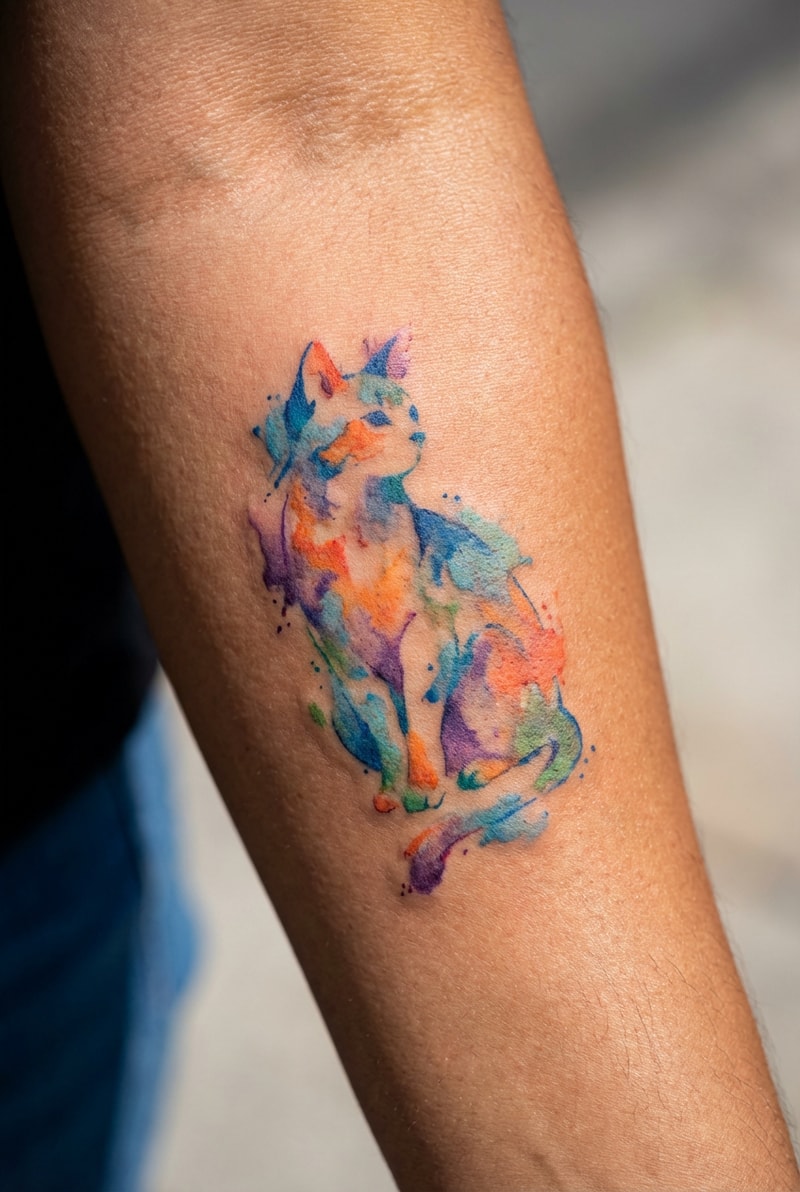
文本到视频:从描述生成电影级剪辑
输入一个场景描述,Seedance 2.0 将在不到3分钟内生成一个720p视频剪辑,具有电影级构图、准确照明和自然的基于物理的运动。该模型理解文本形式的导演级相机指令('dolly zoom on subject'、'orbit left 90 degrees'、'handheld tracking shot')。输出剪辑为3–8秒的720p,适用于社交媒体、品牌内容和视频故事板。
图像到视频:使用物理准确运动动画化照片
上传一张静态图像作为视觉起点,Seedance 2.0 将生成一个延续视频,具有物理准确的对象和角色运动。该模型推断真实世界的运动约束——织物随风物理运动,水面逼真地荡漾,人类运动遵循自然生物力学。适用于产品动画、肖像视频和概念艺术故事板。
音频参考视频:视觉与声音匹配
上传一个音频文件(音乐、旁白、音效),Seedance 2.0 将生成一个同步视频剪辑,其中视觉运动、节奏和能量匹配音频时间线。多模态音频-视频联合架构同时渲染音频和视频,而不是为预渲染剪辑配音——产生比传统后期制作工具更紧密的音频-视觉同步。适用于音乐视频预告、播客内容和音频驱动的品牌广告。
为什么创作者选择在 MyShell 上使用 Seedance 2.0
原生音频-视频联合生成(非配音)
Seedance 2.0 使用统一的 multimodal 音频-视频联合生成架构(ByteDance, 2026),它从同一生成过程同时渲染音频和视频。这与基于配音的方法(Sora, Gen-4, Kling)根本不同,后者是在预渲染视频中添加音频。原生联合生成产生更紧密的视听同步 — 特别是对于音乐视频和音频驱动的内容,其中节拍对齐很重要。
文本中的导演级相机控制
Seedance 2.0 理解用文本书写的精确摄影指令:'dolly zoom'、'orbit left 90 degrees'、'handheld tracking shot'、'static locked-off wide angle'。Runway Gen-4 和 Kling AI 需要手动相机控制 UI;Seedance 2.0 从纯文本提示执行导演级相机工作。输出为 720p、24fps,每剪辑 3–8 秒,在 3 分钟内渲染。
在 MyShell 上免费:无限制,无水印
通过 fal.ai API 的 Seedance 2.0 每秒生成视频成本为 $0.05–0.12。Runway Gen-4 为 625 积分(~25 video clips)每月 $15;Kling AI 为 660 积分每月 $9.99。MyShell 为标准用户提供免费的 Seedance 2.0 生成,无需订阅、无水印,且无每日剪辑上限。
如何使用 Seedance 2.0 生成视频
步骤 1:选择您的输入模式
选择文本、图像或音频作为您的输入。对于文本到视频,请撰写带有摄像机方向的场景描述(例如 'tracking shot of a person walking through a forest, morning fog, cinematic lighting')。对于图像到视频,请上传最多 10 MB 的 JPG/PNG。对于音频到视频,请上传最多 20 MB 的 MP3/WAV。
步骤 2:Seedance 2.0 生成您的剪辑
统一的多模态架构处理您的输入,并在一次通过中同时生成音频和视频。根据您的文本提示自动应用物理准确的运动模拟和导演摄像机控制。不需要手动摄像机路径配置或后期音频同步。

步骤 3:30–60 秒内下载 720p 视频
您的 3–8 秒 720p MP4 剪辑将在不到 3 分钟内准备就绪。没有水印,没有订阅,没有每日上限。立即下载以直接用于社交媒体、演示文稿或视频编辑时间线。